Ship OpenTelemetry Data to Coralogix via Reverse Proxy (Caddy 2)
It is commonplace for organizations to restrict their IT systems from having direct or unsolicited access to external networks or the Internet, with network proxies serving…

In this article, we’ll learn about the Elasticsearch flattened datatype which was introduced in order to better handle documents that contain a large or unknown number of fields. The lesson examples were formed within the context of a centralized logging solution, but the same principles generally apply.
By default, Elasticsearch maps fields contained in documents automatically as they’re ingested. Although this is the easiest way to get started with Elasticsearch, it tends to lead to an explosion of fields over time and Elasticsearch’s performance will suffer from ‘out of memory’ errors and poor performance when indexing and querying the data.
This situation, known as ‘mapping explosions’, is actually quite common. And this is what the Flattened datatype aims to solve. Let’s learn how to use it to improve Elasticsearch’s performance in real-world scenarios.
When faced with handling documents containing a ton of unpredictable fields, using the flattened mapping type can help reduce the total amount of fields by indexing an entire JSON object (along with its nested fields) as a single Keyword field.
However, this comes with a caveat. Our options for querying will be more limited with the flattened type, so we need to understand the nature of our data before creating our mappings.
To better understand why we might need the flattened type, let’s first review some other ways for handling documents with very large numbers of fields.
The Nested datatype is defined in fields that are arrays and contain a large number of objects. Each object in the array would be treated as a separate document.
Though this approach handles many fields, it has some pitfalls like:
We can disable fields that have too many inner fields. By applying this setting, the field and its contents would not be parsed by Elasticsearch. This approach has the benefit of controlling the overall fields but;
The Elasticsearch flattened datatype has none of the issues that are caused by the nested datatype, and also provide decent querying capabilities when compared to disabled fields.
The flattened type provides an alternative approach, where the entire object is mapped as a single field. Given an object, the flattened mapping will parse out its leaf values and index them into one field as keywords.
In order to understand how a large number of fields affect Elasticsearch, let’s briefly review the way mappings (i.e schema) are done in Elasticsearch and what happens when a large number of fields are inserted into it.
One of Elasticsearch’s key benefits over traditional databases is its ability to adapt to different types of data that we feed it without having to predefine the datatypes in a schema. Instead, the schema is generated by Elasticsearch automatically for us as data gets ingested. This automatic detection of the datatypes of the newly added fields by Elasticsearch is called dynamic mapping.
However, in many cases, it’s necessary to manually assign a different datatype to better optimize Elasticsearch for our particular needs. The manual assigning of the datatypes to certain fields is called explicit mapping.
The explicit mapping works for smaller data sets because if there are frequent changes to the mapping and we are to define them explicitly, we might end up re-indexing the data many times. This is because, once a field is indexed with a certain datatype in an index, the only way to change the datatype of that field is to re-index the data with updated mappings containing the new datatype for the field.
To greatly reduce the re-indexing iterations, we can take a dynamic mapping approach using dynamic templates, where we set rules to automatically map new fields dynamically. These mapping rules can be based on the detected datatype, the pattern of field name or field paths.
Let’s first take a closer look at the mapping process in Elasticsearch to better understand the kind of challenges that the Elasticsearch flattened datatype was designed to solve.
First, let’s navigate to the Kibana dev tools. After logging into Kibana, click on the icon (#2), in the sidebar would take us to the “Dev tools”
This will launch with the dev tools section for Kibana:
Create an index by entering the following command in the Kibana dev tools
PUT demo-default
Let’s retrieve the mapping of the index we just created by typing in the following
GET demo-default/_mapping
As shown in the response there is no mapping information pertaining to the index “demo-flattened” as we did not provide a mapping yet and there were no documents ingested by the index.

Now let’s index a sample log to the “demo-default” index:
PUT demo-default/_doc/1
{
"message": "[5592:1:0309/123054.737712:ERROR:child_process_sandbox_support_impl_linux.cc(79)] FontService unique font name matching request did not receive a response.",
"fileset": {
"name": "syslog"
},
"process": {
"name": "org.gnome.Shell.desktop",
"pid": 3383
},
"@timestamp": "2020-03-09T18:00:54.000+05:30",
"host": {
"hostname": "bionic",
"name": "bionic"
}
}
After indexing the document, we can check the status of the mapping with the following command:
GET demo-default/_mapping

As you can see in the mapping, Elasticsearch, automatically generated mappings for each field contained in the document that we just ingested.
The Cluster state contains all of the information needed for the nodes to operate in a cluster. This includes details of the nodes contained in the cluster, the metadata like index templates, and info on every index in the cluster.
If Elasticsearch is operating as a cluster (i.e. with more than one node), the sole master node will send cluster state information to every other node in the cluster so that all nodes have the same cluster state at any point in time.
Presently, the important thing to understand is that mapping assignments are stored in these cluster states.
The cluster state information can be viewed by using the following request
GET /_cluster/state
The response for the cluster state API request will look like this example:
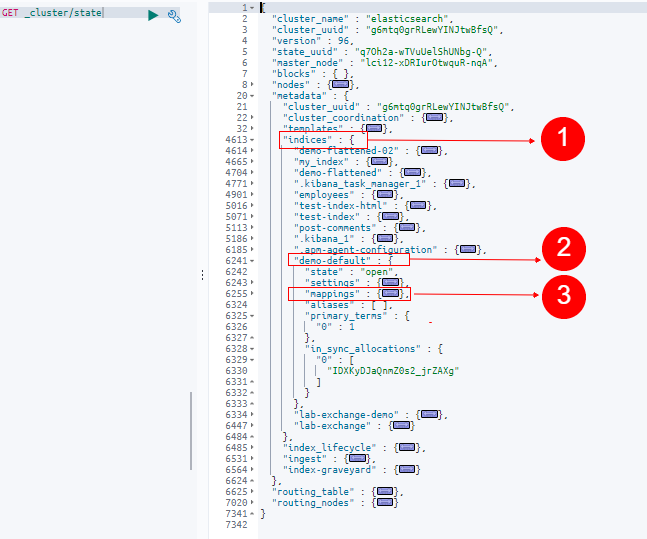
In this cluster state example you can see the “indices” object (#1) under the “metadata” field. Nested in this object you’ll find a complete list of indices in the cluster (#2). Here we can see the index we created named “demo-default” which holds the index metadata including the settings and mappings (#3). Upon expanding the mappings object, we can now see the index mapping that Elasticsearch created.

Essentially what happens is that for each new field that gets added to an index, a mapping is created and this mapping then gets updated in the cluster state. At that point, the cluster state is transmitted from the master node to every other node in the cluster.
So far everything seems to be going well, but what happens if we need to ingest documents containing a huge amount of new fields? Elasticsearch will have to update the cluster state for each new field and this cluster state has to be passed to all nodes. The transmission of the cluster state across nodes is a single-threaded operation – so the more field mappings there are to update, the longer the update will take to complete. This latency typically ends with a poorly performing cluster and can sometimes bring an entire cluster down. This is called a “mapping explosion”.
This is one of the reasons that Elasticsearch has limited the number of fields in an index to 1,000 from version 5.x and above. If our number of fields exceeds 1,000, we have to manually change the default index field limit (using the index.mapping.total_fields.limit setting) or we need to reconsider our architecture.
This is precisely the problem that the Elasticsearch flattened datatype was designed to solve.
With the Elasticsearch flattened datatype, objects with large numbers of nested fields are treated as a single keyword field. In other words, we assign the flattened type to objects that we know contain a large number of nested fields so that they’ll be treated as one single field instead of many individual fields.
Now that we’ve understood why we need the flattened datatype, let’s see it in action.
We’ll start by ingesting the same document that we did previously, but we’ll create a new index so we can compare it with the unflattened version
After creating the index, we’ll assign the flattened datatype to one of the fields in our document.
Alright, let’s get right to it starting with the command to create a new index:
PUT demo-flattened
Now, before we ingest any documents to our new index, we’ll explicitly assign the “flattened” mapping type to the field called “host”, so that when the document is ingested, Elasticsearch will recognize that field and apply the appropriate flattened datatype to the field automatically:
PUT demo-flattened/_mapping
{
"properties": {
"host": {
"type": "flattened"
}
}
}
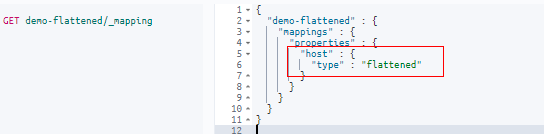
Let’s check whether this explicit mapping was applied to the “demo-flattened” index using in this request:
GET demo-flattened/_mapping
This response confirms that we’ve indeed applied the “flattened” type to the mappings.
Now let’s index the same document that we previously indexed with this request:
PUT demo-flattened/_doc/1
{
"message": "[5592:1:0309/123054.737712:ERROR:child_process_sandbox_support_impl_linux.cc(79)] FontService unique font name matching request did not receive a response.",
"fileset": {
"name": "syslog"
},
"process": {
"name": "org.gnome.Shell.desktop",
"pid": 3383
},
"@timestamp": "2020-03-09T18:00:54.000+05:30",
"host": {
"hostname": "bionic",
"name": "bionic"
}
}
After indexing the sample document, let’s check the mapping of the index again by using in this request
GET demo-flattened/_mapping

We can see here that Elasticsearch automatically mapped the fields to datatypes, except for the “host” field which remained the “flattened” type, as we previously configured it.
Now, let’s compare the mappings of the unflattened (demo-default) and flattened (demo-flattened) indexes.

Notice how our first non-flattened index created mappings for each individual field nested under the “host” object. In contrast, our latest flattened index shows a single mapping that throws all of the nested fields into one field, thereby reducing the amounts of fields in our index. And that’s precisely what we’re after here.
We’ve seen how to create a flattened mapping for objects with a large number of nested fields. But what happens if additional nested fields need to flow into Elasticsearch after we’ve already mapped it?
Let’s see how Elasticsearch reacts when we add more nested fields to the “host” object that has already been mapped to the flattened type.
We’ll use Elasticsearch’s “update API” to POST an update to the “host” field and add two new sub-fields named “osVersion” and “osArchitecture” under “host”:
POST demo-flattened/_update/1
{
"doc" : {
"host" : {
"osVersion": "Bionic Beaver",
"osArchitecture":"x86_64"
}
}
}
Let’s check the document that we updated:
GET demo-flattened/_doc/1
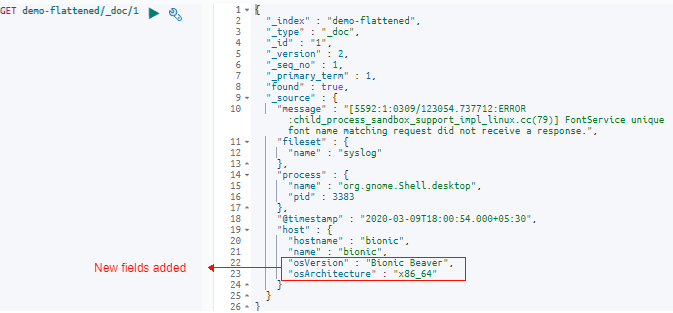
We can see here that the two fields were added successfully to the existing document.
Now let’s see what happens to the mapping of the “host” field:
GET demo-flattened/_mappings
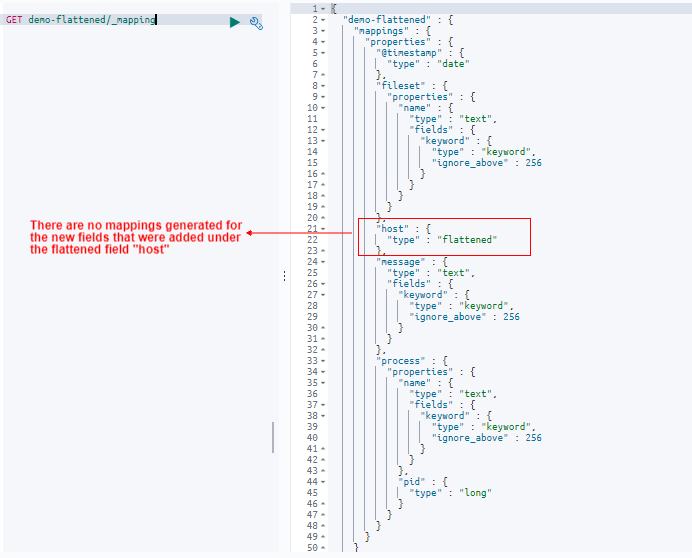
Notice how our flattened mapping type for the “host” field has not been modified by Elasticsearch even though we’ve added two new fields. This is exactly the predictable behavior we want to have happened when indexing documents that can potentially generate a large number of fields. Since additional fields get mapped to the single flattened “host” field, no matter how many nested fields are added, the cluster state remains unchanged.
In this way, Elasticsearch helps us avoid the dreadful mapping explosions. However, as with many things in life, there’s a drawback to the flattened object approach and we’ll cover that next.
While it is possible to query the nested fields that get “flattened” inside a single field, there are certain limitations to be aware of. All field values in a flattened object are stored as keywords – and keyword fields don’t undergo any sort of text tokenization or analysis but are rather stored as-is.
The key capabilities that we lose by not having an “analyzed” field is the ability to use non-case sensitive queries so that you don’t have to enter an exact matching query and analyzed fields also enable Elasticsearch to factor the field into the search score.
Let’s take a look at some example queries to better understand these limitations so that we can choose the right mapping for different use cases.
There are a few nested fields under the field “host”. Let’s query the “host” field with a text query and see what happens:
GET demo-flattened/_search
{
"query": {
"term": {
"host": "Bionic Beaver"
}
}
}
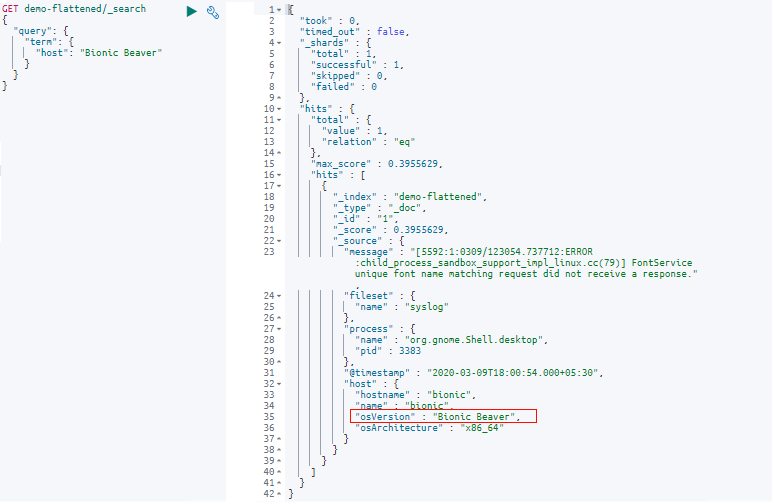
As we can see, querying the top-level “host” field looks for matches in all values nested under the “host” object.
If we need to query a specific field like “osVersion” in the “host” object for example, we can use the following query to achieve that:
GET demo-flattened/_search
{
"query": {
"term": {
"host.osVersion": "Bionic Beaver"
}
}
}
Here in the results you can see we used the dot notation (host.osVersion) to refer to the inner field of “osVersion”.
A match query returns the documents which match a text or phrase on one or more fields.
A match query can be applied to the flattened fields, but since the flattened field values are only stored as keywords, there are certain limitations for full-text search capabilities. This can be demonstrated best by performing three separate searches on the same field
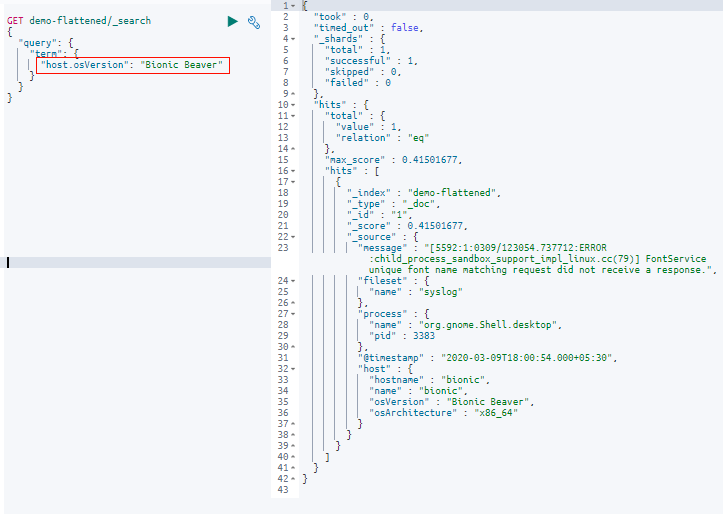
Let’s search the field “osVersion” inside the “host” field for the text “Bionic Beaver”. Here please notice the casing of the search text.
GET demo-flattened/_search
{
"query": {
"match": {
"host.osVersion": "Bionic Beaver"
}
}
}
After passing in the search request, the query results will be as shown in the image:
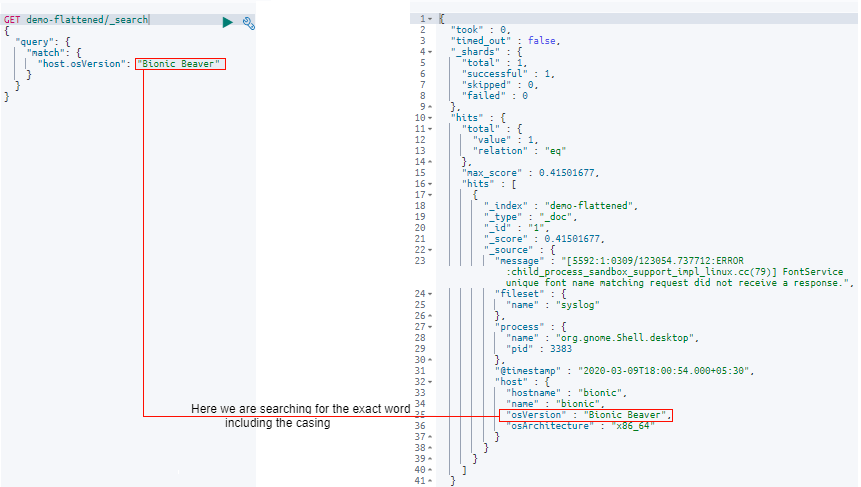
Here you can see that the result contains the field “osVersion” with the value “Bionic Beaver” and is in the exact casing too.
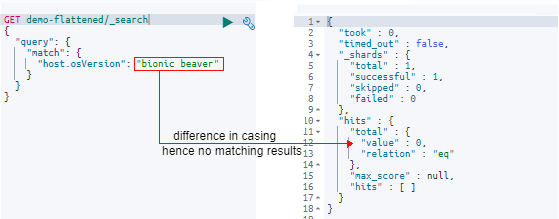
In the previous example, we saw the match query return the keyword with the exact same casing as that of the “osVersion” field. In this example, let’s see what happens when the search keyword differs from that in the field:
GET demo-flattened/_search
{
"query": {
"match": {
"host.osVersion": "bionic beaver"
}
}
}
After passing the “match” query, we get no results. This is because the value stored in the “osVersion” field was exactly “Bionic Beaver” and since the field wasn’t analyzed by Elasticsearch as a result of using the flattening type, it will only return results matching the exact casing of the letters.
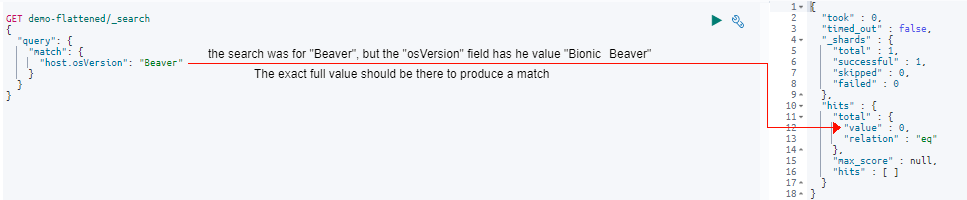
Moving to our third example, let’s see the effect of querying just a part of the phrase of “Beaver” in the “osVersion” field:
GET demo-flattened/_search
{
"query": {
"match": {
"host.osVersion": "Beaver"
}
}
}
In the response, you can see there are no matches. This is because our match query of “Beaver” doesn’t match the exact value of “Bionic Beaver” because the word “Bionic” is missing.
That was a lot of info, so let’s now summarise what we’ve learned with our example “match” queries on the host.osVersion field:
| Match Query Text | Results | Reason |
| “Bionic Beaver” | Document returned with osVersion value as “Bionic Beaver” | Exact match of the match query text with that of the host.os Version’s value |
| “bionic beaver” | No documents returned | The casing of the match query text differs from that of host.osVersion (Bionic Beaver) |
| “Beaver” | No documents returned | The match query contains only a single token of “Beaver”. But the host.osVersion value is “Bionic Beaver” as a whole |
Whenever faced with the decision to flatten an object, here’s a few key limitations we need to consider when working with the Elasticsearch flattened datatype:
In summary, we learned that Elasticsearch performance can quickly take a nosedive if we pump too many fields into an index. This is because the more fields we have the more memory required and Elasticsearch performance ends up taking a serious hit. This is especially true when dealing with limited resources or a high load.
The Elasticsearch flattened datatype is used to effectively reduce the number of fields contained in our index while still allowing us to query the flattened data.
However, this approach comes with its limitations, so choosing to use the “flattened” type should be reserved for cases that don’t require these capabilities.
It is commonplace for organizations to restrict their IT systems from having direct or unsolicited access to external networks or the Internet, with network proxies serving…

AWS Systems Manager and CloudWatch Agent provide an integrated approach to observability and managing your AWS infrastructure efficiently. In this tutorial, I will show you how…

Infrastructure as Code is an increasingly popular DevOps paradigm. IaC has the ability to abstract away the details of server provisioning. This tutorial will look at…