
Coralogix’s Streama Technology: The Ultimate Party Bouncer
Coralogix is not just another monitoring or observability platform. We’re using our unique Streama technology to analyze data without needing to index it so teams can…

In the observability toolchain, all of our efforts go into data storage and analysis, and the usability of our system becomes a second-class citizen. Autocomplete is a crucial usability feature that significantly improves the developer experience. It is ubiquitous amongst engineering tools from IDEs to CLIs. Autocomplete has long been a feature of many observability tools, but they all miss a crucial detail – optimizing for developer productivity. Let’s discuss how many observability tools don’t focus on this and how Coralogix is paving the way.
If we begin with Kibana, we can see a very basic autocomplete dialog. However, this doesn’t come with the free version of Kibana and requires a license purchased from Elastic.
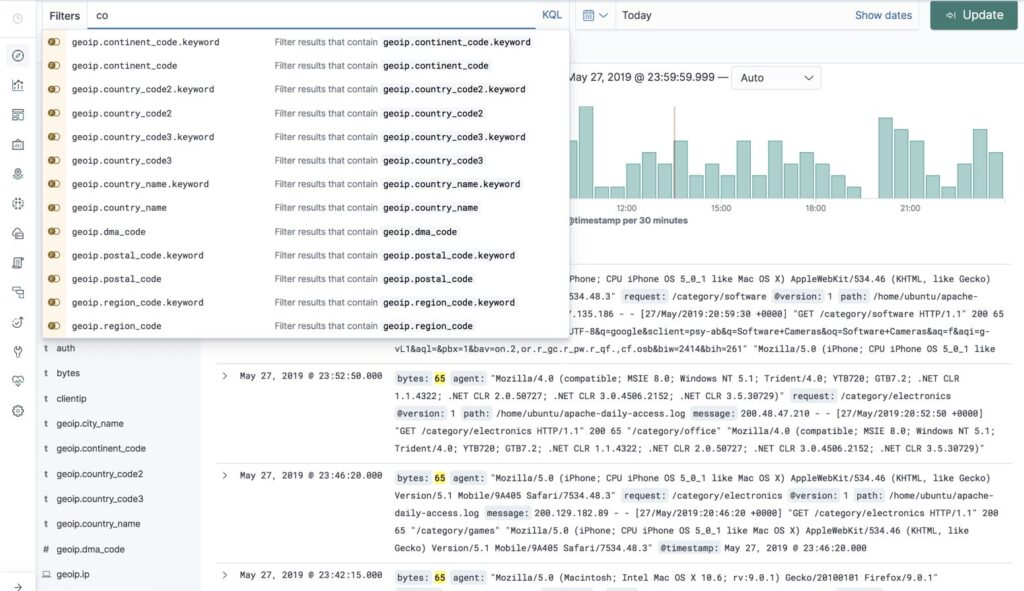
Autocomplete across the observability industry looks like this, and while efforts have been made to fix these issues, there is still a long way to go for many providers, both SaaS and open source. In the above screenshot, no attempt has been made to filter these values based on the time range. You’re simply presented with everything, but this isn’t the only way autocomplete has failed in observability.
There are three key ways in which all observability autocomplete is missing the point right now:
At Coralogix, we focus on giving our customers excellent data analysis capabilities. We want to make it simple to discover their data. Logs and metrics typically build up thousands of different fields over time. It’s our job to cut through the noise and give our customers the most precise information we can.
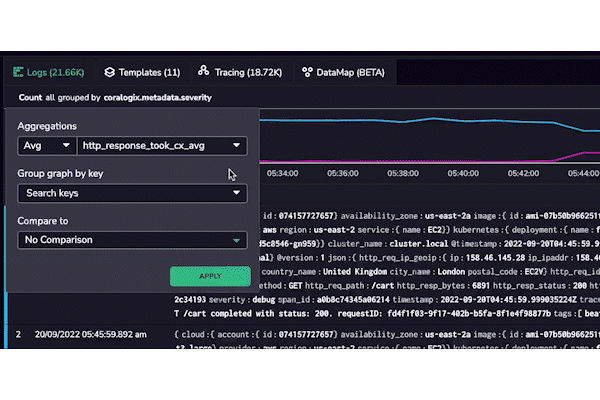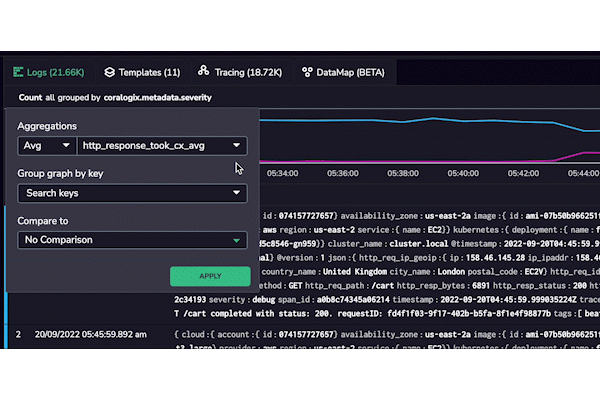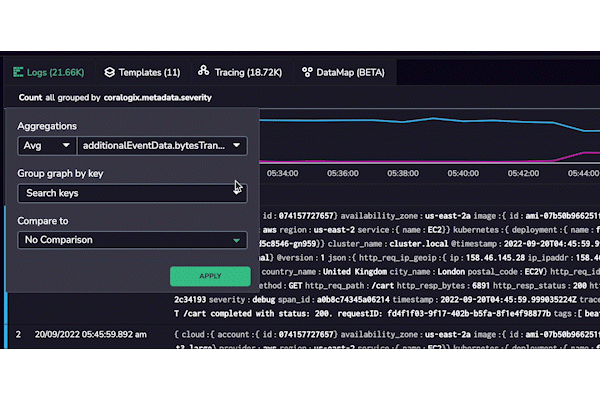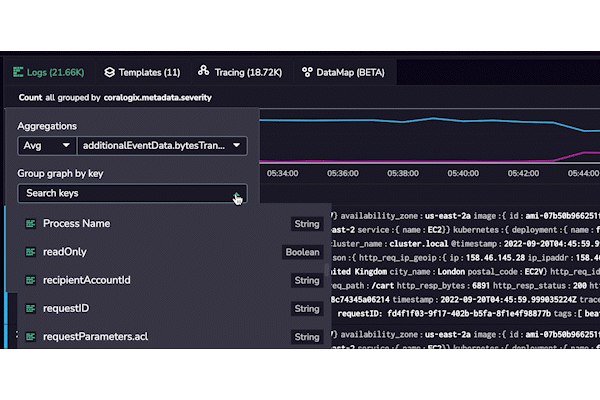
Coralogix won’t bombard a user with every possible label when aggregating their metrics. Instead, it will automatically filter the values based on the labels already associated with their metrics. It does this by tracking the schema for each log and metric and dynamically updating it when new values appear. This means that the user only sees the labels and indexed fields in the schema for that log or metric, which has another layer of complexity.
The time-series nature of observability data means that a given key may only exist at a certain point in time. If a user queries their data over an hour, there may be more labels or indexed fields than if they query over 15 minutes. This is the nature of logs and metrics.
At Coralogix, we fundamentally understand this problem and only show our users the fields that exist in the timeframe they’re querying, rather than just showing them every detected field. This means that we only display the data that is useful and contextual, removing the noise, minimizing pointless searching, and allowing our users to discover more and more about their data.
When aggregating fields in your logs, it doesn’t make sense to show the non-numeric fields. At Coralogix, we track the schemas for our customers’ data over time, and we know the availability and type of every variable. Coralogix will only render the most relevant fields when you begin to type.
This type of intelligent autocomplete is akin to the sophistication seen in modern IDEs, where engineers have grown used to this support from their automation. At Coralogix, we are building our interface like an IDE, so engineers can feel at home while they explore their data.
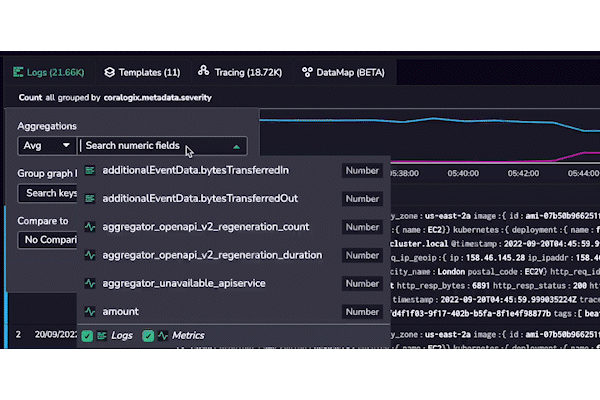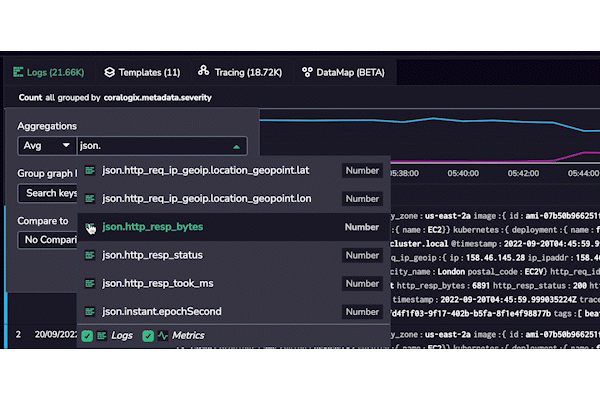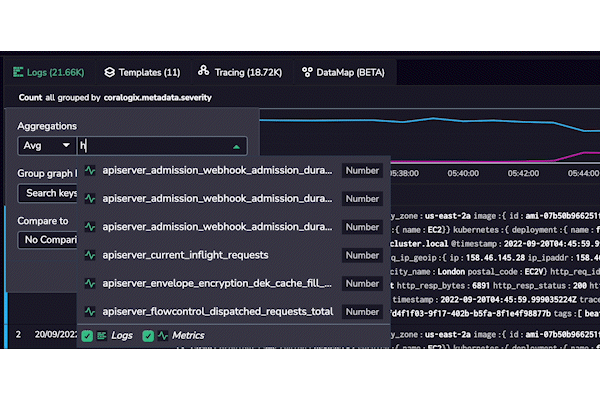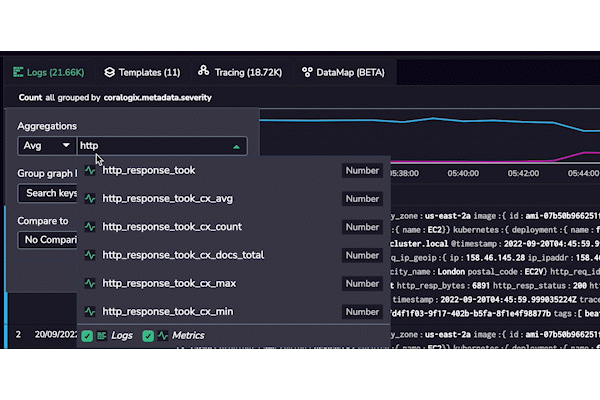
At Coralogix, we don’t believe in information silos. That’s why we will render indexed fields from logs and any available metrics as part of our autocomplete functionality. This is a consistent theme throughout our entire platform – full-stack observability.
At Coralogix, we believe that the details make for an excellent developer experience. Contextual autocomplete is just one of many different features we have made available so that using our platform is as simple as possible, enabling our customers to unlock all of the value hidden away within their logs, metrics, traces, and security data.
Coralogix is not just another monitoring or observability platform. We’re using our unique Streama technology to analyze data without needing to index it so teams can…

Tracing is often the last thought in any observability strategy. While engineers prioritize logs and metrics, tracing is truly the hallmark of a mature observability platform,…
Stateful, commonly monolithic, and absolutely fundamental to system design, the quality of your database administration and operation is a key determinant of your overall success. Databases…