Save time and stay ahead with Coralogix Scheduled Reports
As your data continues to grow and time remains critical, making data-driven decisions has never been more important (and let’s face it, that’s no small feat)….

At Coralogix, we strive to ensure that our customers get a stable, real-time service at scale. As part of this commitment, we are constantly improving our data ingestion pipeline resiliency and performance.
Coralogix ingests messages at extremely high rates — up to tens of billions of messages per day. Every one of these records needs to go through our entire pipeline at near real-time rates: validation, parsing, classification, and ingestion to Elasticsearch.
In the past, we had services in our ingestion pipeline consuming messages from Kafka, performing their workload, and producing the messages to the next topic in the pipeline. The workload consisted of a mixture of external I/O and in-memory processing. The external I/O was necessary for writing and pulling data from various sources (relational database, Redis, Couchbase, etc.). As our scale grew, we saw that our processing rate was not scaling linearly and was highly sensitive to infrastructure glitches.
As we see it, a scalable service is bounded by the machine’s CPU. When traffic increases, the CPU usage should increase linearly. In our case, we were forced to scale out our services despite the CPU not being a bottleneck. At some point, one of our services had to run on 240 containers (!). We then decided that we’re due for a redesign.
We started with the most straightforward design possible: a cache that will be populated on-demand with a configurable expiration time. For each message, the mechanism checked that the required data was cached and retrieved it when necessary. It did improve read performance, but some issues persisted.
Not what we wanted
We decided to do a full redesign and reach a point where our services where bounded entirely by CPU, without any time wasted on external I/O. After considering a few platforms, we decided that Kafka Streams was the right solution for us.
The idea behind Kafka Streams and Kafka Connect is having all your data available in Kafka.
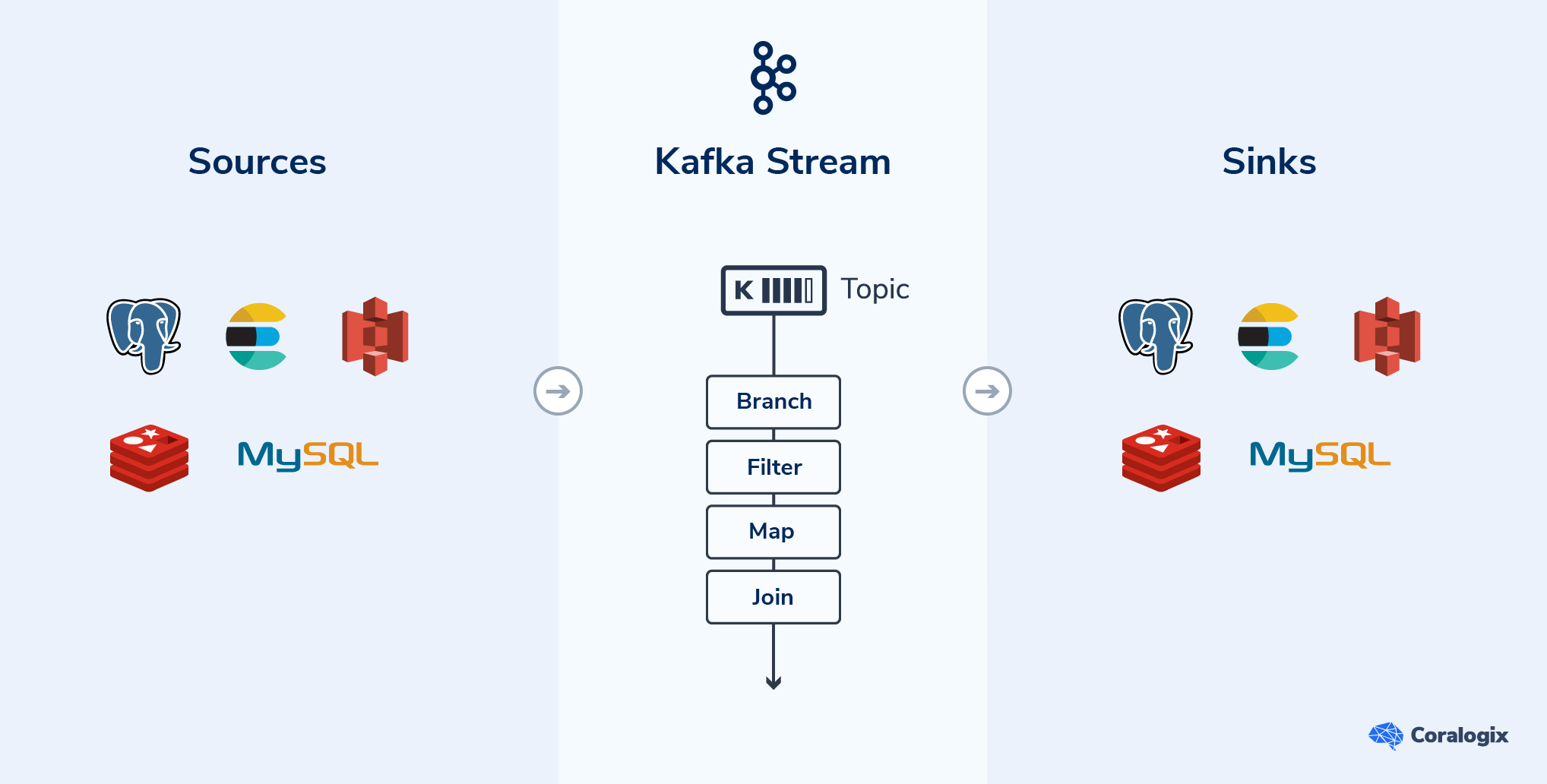
We can split the design into three types of components — the 3 S’s:
Source: a source is anything that ingests data from external sources into a Kafka topic. For example, a REST server, a database, etc. In addition to custom sources implemented by our services, Kafka Connect provides many plugins that implement different sources (Relational databases, Elasticsearch, Couchbase, and more).
Stream: The stream is where it all comes together, and your business logic is executed. The stream consumes the data from the source topics and creates a GlobalKTable or KTable from them. The main data flow then uses these tables to enrich incoming records as part of the workload.
Sink: Consumes data from a topic and ingests it to an external data source. Kafka Connect has sink connectors, however, we prefer using Akka stream to write our own sinks (maximum flexibility).
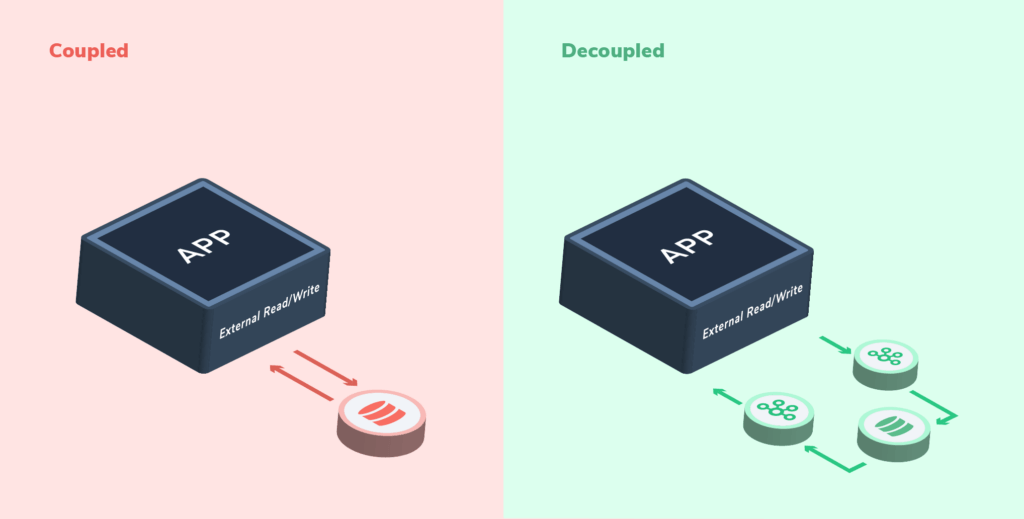
Advantages: Light, easy to get started, overall easy to maintain, provides a push-updated cache, relies only on Kafka.
From our experience, the main advantage of the Kafka Streams platform is the fact that it is opinionated and makes it harder to execute external side effects as part of the stream.
Disadvantages: Complex stateful transformations like sliding windows and even group by are not handled well from our experience, particularly with hot partitions (i.e., key skew). This can be addressed by spreading the keys which will require two sliding windows — not fun.
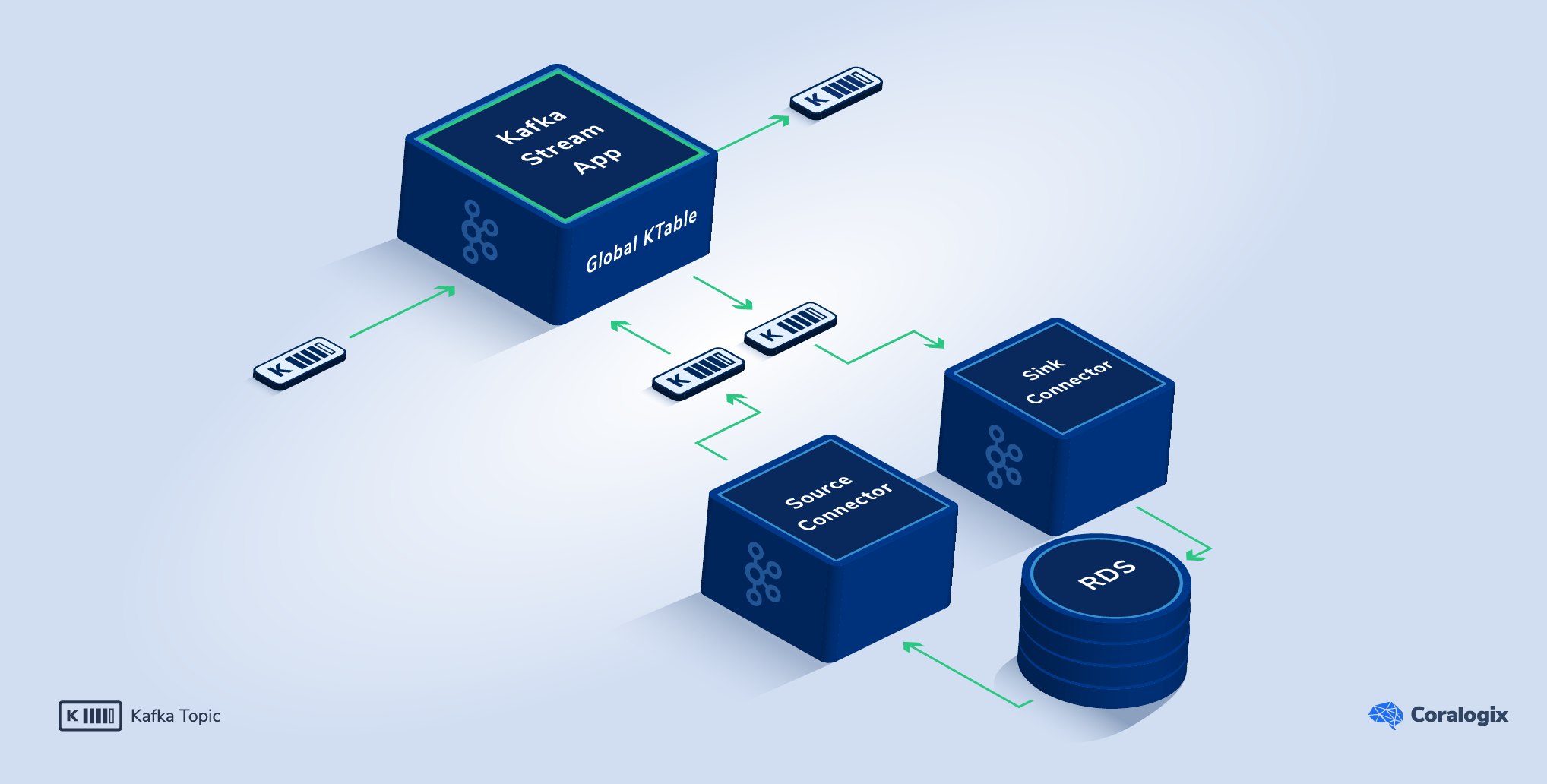
We started by ingesting all of our data sources to Kafka topics using Kafka Connect plugins, which produce the data to multiple Kafka topics.
The main data stream is received by a RESTful HTTP API which validates the incoming data and produces it to a Kafka topic.
The Kafka Streams-based service consumes all the source topics and creates GlobalKTable stores based on RocksDB. Whenever the external source changes, the connector produces a message to the topic. The service consumes the message and updates the store. During the streaming process, the incoming data is enriched with the data from the GlobalKTable to execute the workload.
Look at that! We got a ‘push-updated’ cache with no delays and no external side effects. Thank you, Kafka Streams 🙂
What if we need to update an external datastore? If during the workload processing, the service needs to update a store, it will produce a message to a Kafka topic. We create different decoupled microservice sinks that will consume the data and ingest it into the stores after the workload processing is completed.
In real-world examples, like our full solution, you can easily have many sources and sink topics in use by a single Kafka Streams application.
Looking good, but can we do even better?
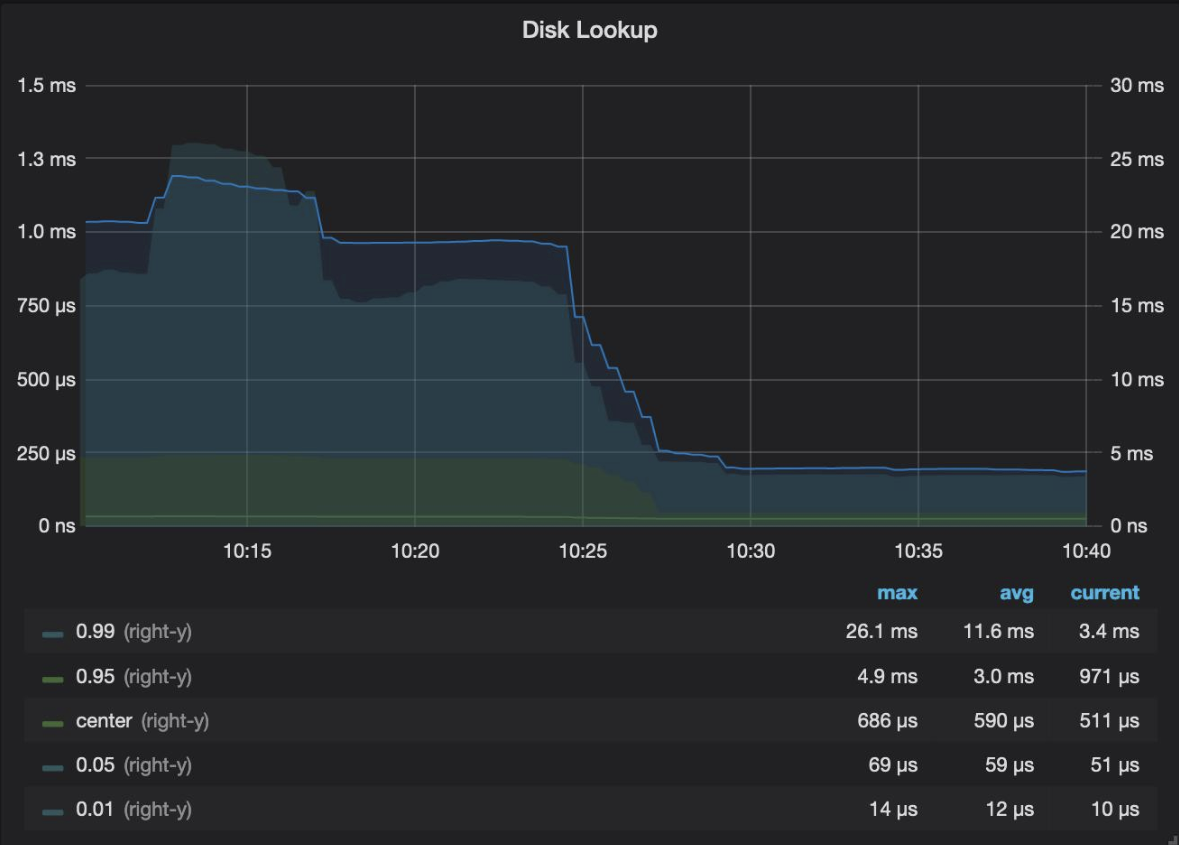
This was already a meteoric step forward. However, one thing still bugged us. The disk lookup latency for retrieving and deserializing items from RocksDB was taking 33% of the total time to handle a message. We started with optimizing RocksDB:
All of these changes yielded some improvements, but we were still not satisfied. It was only then that we added another layer of in-memory LRU cache for deserialized objects. We were finally happy with the new performance, as can be seen in these latency charts:
By decoupling our external sources from our stream app and bring the required data close to our app, we were able to increase the stability and performance of our main pipeline. Kafka Stream & Kafka Connect made a lot of the heavy lifting and helps us stay in the right track going forward.
It is an exciting time to join Coralogix’s engineering team. If this sounds interesting to you, please take a look at our job page – Work at Coralogix. If you’re particularly passionate about stream architecture, you may want to take a look at these two openings first: FullStack Engineer and Backend Engineer.
Thanks for reading. Drop us a message if you have questions or want to discuss more how we use Kafka Streams.
Special thanks to Zohar Aharon & Itamar Ravid for being the pioneers of the new design!
For an introduction on Kafka, see this tutorial.
As your data continues to grow and time remains critical, making data-driven decisions has never been more important (and let’s face it, that’s no small feat)….
In the fast-paced world of business, timely and accurate incident investigations are crucial. The ability to piece together evidence, understand the timeline, and collaborate effectively is…

Becoming an expert in any query language can take years of dedicated study and practice. At Coralogix, however, we believe observability should be accessible to everyone….