
Mastering Null Semantics: Translating SQL Expressions to OpenSearch DSL
Working at Coralogix, a leading full-stack observability platform, I recently faced an interesting challenge. The team I am part of is building the DataPrime query language…

GraphQL is an open-source query and manipulation language to use for APIs. It contains server-side functionality and a query language for maintaining data interfaces. It was first created in 2012 by Facebook and publicly released in 2015. Since 2018, the GraphQL project has been hosted by the Linux Foundation and run by the GraphQL Foundation.
In this GraphQL introduction, we will discuss what is unique about GraphQL APIs, show how to set up a simple schema and resolvers, and introduce some tools that will be useful as you develop your own API.
There are critical aspects to GraphQL that make it unique from other web services. GraphQL allows users to build APIs with a single HTTP endpoint that fetches and alters data from multiple backend data sources. The format of the query is directly related to the structure of the returned data.
This connection between the request format and returned data allows the client to control the GraphQL API returned data. Since your API defines the data formats in the GraphQL schema, the API can be made self-documenting and may relate directly to data stored in multiple sources if needed.
While using GraphQL, there is no requirement for using a specific database configuration. Instead, GraphQL uses code to interface with whichever data structure you want to support. GraphQL bases its framework on the definition of types that are user-constructed to meet the data requirements. The types define what is sent from the server-side environment to the web (or other) service. The service defines what data it wants to receive based on the type definition.
The GraphQL language uses definitions of so-called schemas to set up its API model. It uses an object-like notation called the GraphQL schema language, which defines what data is available in queries and mutations. Schemas allow users to define basic object types that describe the information sent to and received from the GraphQL interface.
In each case, a field may be made required or optional. Setting a field as optional allows flexibility to limit the amount of data used in the interface to only what is needed. A call to the same mutation or query may occur in multiple ways, with different pieces of the result being requested and returned. Also, developers may change schemas without releasing a new version of the API, a significant difference from classic REST APIs.
Let’s walk through a simple example to show how the description above might work.
We may have a set of queries and mutations that show a listing of bands and their works. Below is a simple example of a schema that could convey this information. The server-side function defines the schema containing all the fields available to the client.
There are some essential subtitles in this example to note:
const typeDefs = ` type Music { bandName: String! numberOfAlbums: Int albums: [Album] } type Album { albumName: String! members: [Musician] genre: Genre } type Musician { firstName: String! lastName: String! } enum Genre { classicRock country jazz pop punk } `
In GraphQL, resolvers are either a query that returns specific data objects to the client or a mutation that changes the data on the backend somehow. Queries and mutations have similar structures but should be separated logically.
Fields are attributes that the client may request from the backend. The client can expect to receive data in the same format in which it requests it. The following example shows the client requesting Music information. The query itself only requests some of the available data (omitting the available albums field).
{ music { bandName numberOfAlbums }
Here are the results of that request:
{ "data": { "music": [ { "bandName": "The Beatles", "numberOfAlbums": 12 }, { "bandName": "U2", "numberOfAlbums": 14 } ] } }
The results include only fields that were requested and are in the format of the request. If some data was not available and the field is not required, the GraphQL service automatically sets that returned data to null.
Resolvers also allow for definitions of arguments. In GraphQL, users can define input arguments for the resolver in the schema with a new type called input, or each field may also be sent with an argument.
In the example below, an input is defined and used in the getBandDetails query. This input allows the client to request a specific band or even request details for all bands that put out a certain number of albums. The response will be an array of band details formatted as type Music defined in the first example above.
Setting inputs in this way allows us to use the same query filtering on different input details. If you want to require an input, add an ! after a field in the input. Doing this will cause GraphQL to throw an error if that value is missing from the input.
const typeDefs = ` input getBand { bandName: String numberOfAlbums: Int } type Query { music(getBand): [Music] } `
Once the schema is defined, you can code in the logic of the resolvers. Schema stitching allows you to add many resolvers and develop them as microservices. This is not a requirement to use GraphQL, but if you will be doing anything more than 2 or 3 resolvers, you will want to consider splitting it up logically for easy maintainability of code.
If you are using Javascript, a library called graphql-tools can be used to combine the separately coded resolvers into a central schema file to use in your GraphQL API.
Languages
GraphQL is available in many different programming languages. These include JavaScript, Python, Flutter, C/C++, and Swift. Some of the support for the less-popular languages is not ideal. For example, the library for the C/C++ GraphQL parser was last updated in October 2017. However, popular languages like JavaScript and Python are updated much more frequently.
For a complete list of language support, see the GraphQL code page.
Apollo
Apollo is an open-source library built to support GraphQL clients and servers. It also includes tools to support your graphical interface. There may be a charge included depending on how you want to collaborate with your team using Apollo. However, you can easily use the open-source frameworks available to build your APIs.
Apollo Client
The Apollo Client is a state management library for JavaScript that allows users to manage data from GraphQL. Apollo will allow web services to get, cache, and modify server-side data with GraphQL with limited web service setup. The client is available for React, iOS, or Android.
Apollo Server
The Apollo server is a community-maintained library for the GraphQL server which runs on any Node.js HTTP server framework. It can be used as a stand-alone GraphQL server (including serverless), as an add-on to Node.js middleware (like Express), or as a gateway for a federated data graph.
The Apollo server code is used to link your backend data sources with the HTTP interface. It allows users to define GraphQL schema and create mutations and queries which are used by GraphQL. Integrations that would use the Apollo server include Express, Amazon Lambda, Azure Functions, and more.
Typically integrations will have their own Apollo libraries for installation. For example, you can use the apollo-server-lambda npm package when you want to run the GraphQL server on a Lambda function.
Since GraphQL is based on a schema, documentation can be generated by simply pointing a tool at your HTTP Endpoint. Many tools have been built that allow for automatic documentation. The following is a shortlist of currently-maintained options.
GraphiQL is a GUI allowing users to edit and test their resolvers as well as being an interface to auto-generated documentation. It will show you all possible queries, mutations, and types. It also remains updated as you change your code so you always have the latest version displayed.
DocQL is in an open beta testing phase and beta testers will get discounted prices for ongoing use. This service will monitor your API in real-time and update documentation according to the available schema.
graphDoc is an open-source library that will generate a static page for documenting your GraphQL schema.
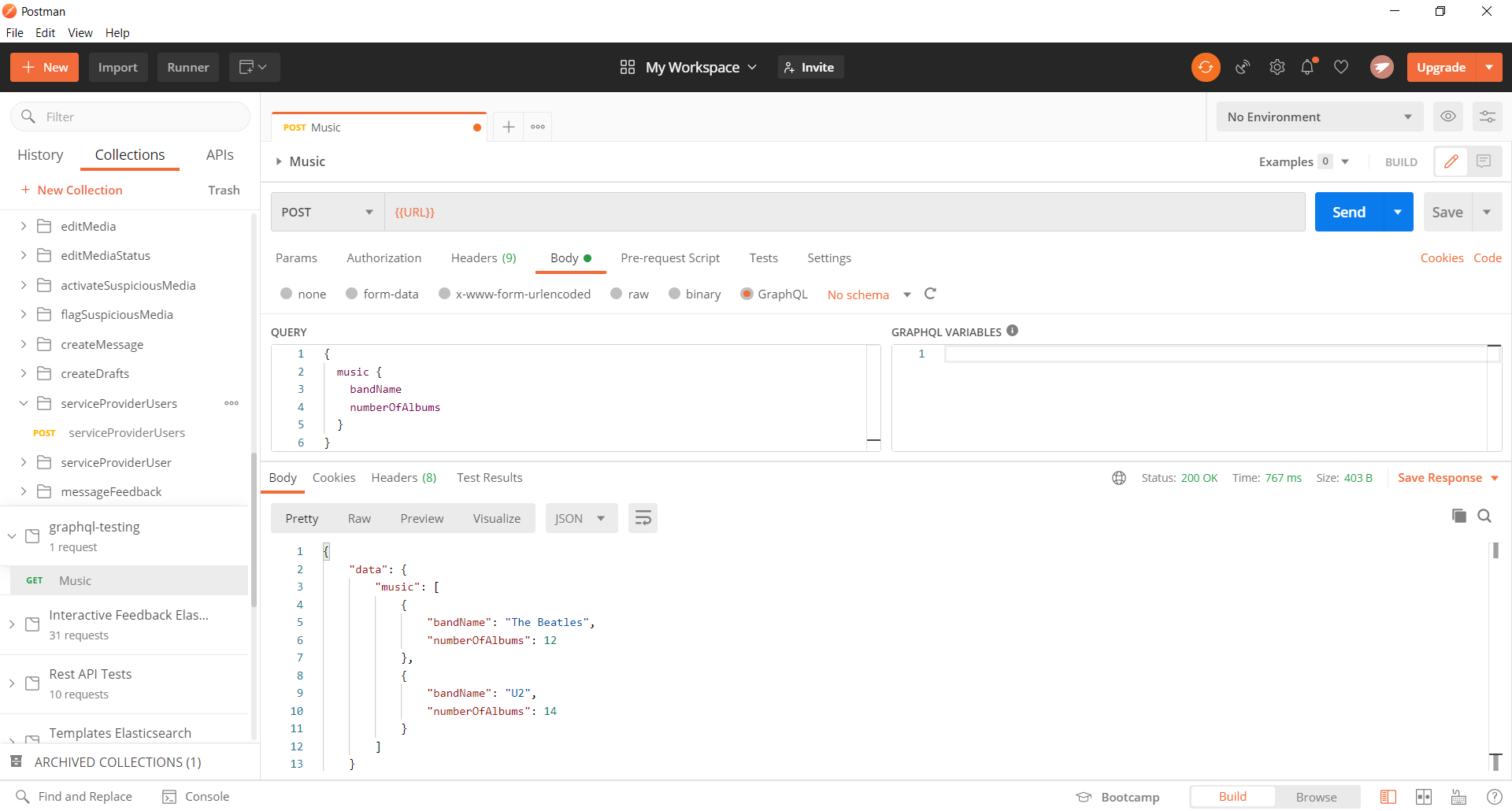
When you are testing your backend software, you can use Postman to test your resolvers before having a client web service or app ready. Postman includes a GraphQL type in its available Body options. Using a POST, set the URL to either the deployed API Gateway or a local host running your GraphQL schema. Set the query to appear as the Fields example.
If you use a mutation instead, you must include the keyword mutation in the resolver input as shown below. The result should be an object matching the request input.
Insomnia is another tool that you can use to test your GraphQL endpoint. It has more-or-less the same features as Postman making it a good alternative. That said, if you are going to put custom authorization into your HTTP endpoint, Insomnia is not able to handle the setup requirements as easily as Postman. It does have a rich interface and is very simple to use, allowing users to create workspaces and share files and projects with other developers very easily.
In this GraphQL introduction, we’ve seen how GraphQL is a powerful API language and framework that allows developers to define exactly what data is available. It enables developers to get around some of the common headaches associated with REST APIs like maintaining multiple endpoints and keeping previous versions alive after revisions.
This GraphQL introduction showed the simplicity of the code needed to set up your first GraphQL API and introduced some tools to help you develop and debug the code as you go.

Working at Coralogix, a leading full-stack observability platform, I recently faced an interesting challenge. The team I am part of is building the DataPrime query language…
Coralogix supports logs, metrics, traces and security data, but some organizations need a multi-vendor strategy to achieve their observability goals, whether it’s developer adoption, or vendor…

Akka’s license change has surprised many of us, but it didn’t come out of nowhere. Lightbend recently announced that Akka will be transitioning from an “Open…