4 Killer Coralogix Tracing Features
Tracing is often the last thought in any observability strategy. While engineers prioritize logs and metrics, tracing is truly the hallmark of a mature observability platform,…

Have you ever tried to find a bug in a multi-layered architecture? Although this might sound like a simple enough task, it can quickly become a nightmare if the system doesn’t have proper monitoring. And the more distributed your system is, the more complex it becomes to analyze the root cause of a problem.
That’s precisely why observability is key in distributed systems. Observability can be thought of as the advanced version of application monitoring. It helps engineers gain visibility into a system by analyzing the three pillars of observability — logs, metrics and traces.
While there is some overlap between the three data points, tracing helps provide a holistic view of application performance. Traces follow a request throughout its lifecycle of interacting with different components and record data about how each service has performed.
This article will explain distributed tracing and how it works in microservices.

Microservices Observability have become pretty popular, and with good reason, too — they allow businesses to scale vertically and rapidly. However, they also increase complexity.
Think of it this way: when you want to scale a business unit, you’d like to make smaller teams that can work efficiently on a single task. Such as a frontend team who can handle UI/UX tweaks on your website or a backend team to manage order fulfillment.
But now, you also have to think about how your front-end team will communicate with your backend team. If there’s any delay in response from either side or how they work, the customer’s order can get stuck.
Applications behave similarly. In distributed systems, dozens or even hundreds of services depend on the responses of application calls. Analyzing where a call originated from and where it is breaking is difficult, especially when a single team cannot fully understand how individual services interact with each other.
Even if you enable traditional log monitoring on an application, you only get the overall response time of a microservice. So, how do you understand which piece of code or service is responsible? More importantly, how do you resolve it before it affects customers?
The answer lies in using observability to your advantage. Observability goes beyond traditional monitoring by combining logs, metrics, security, and traces to troubleshoot application performance issues quickly. However, most companies haven’t yet integrated the most important aspect of observability to their stack: distributed tracing.
Distributed tracing in microservices provides a bird’s eye view of a request traversing every single component of a vast network of services. Kind of like a manager knowing exactly how his team works, right down to the individual response times and how they interact with each other. Neat, right?
In applications, traces break down the time each component takes so that you can quickly pinpoint the source of a performance bottleneck. This data can then be overlaid with logs and metrics to focus your optimization efforts.
Here’s how it works in practice.
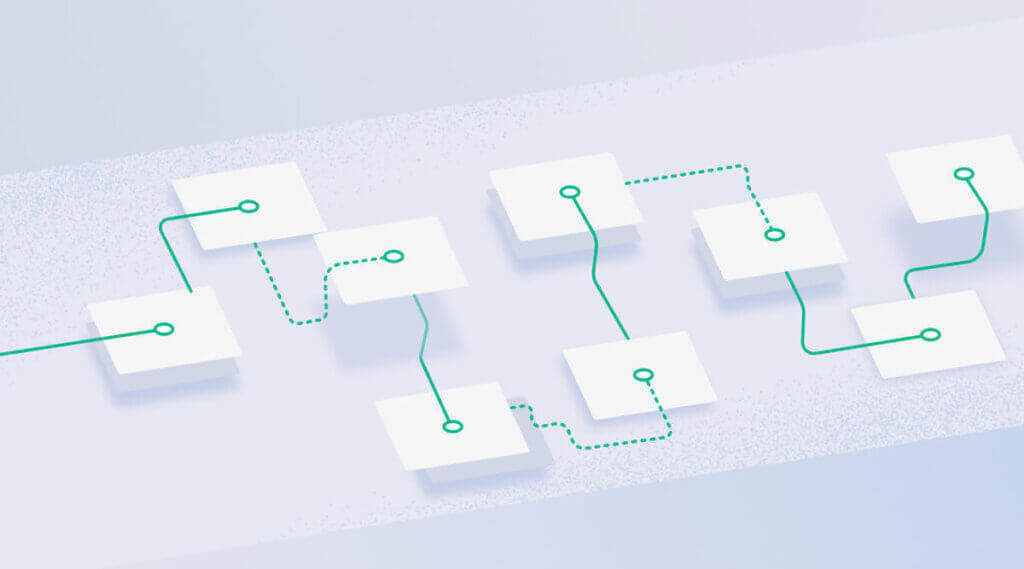
In a distributed system, a request generally spans different microservices and returns a response to the function that triggered it. A trace follows this request over multiple spans, gathering data on how each service has performed. This data can be linked together through a unique correlation ID, or trace ID.
Thus, distributed tracing can help you visualize the request as it flows through each system component. But, of course, tracing needs to be implemented in each microservice to achieve this.
Before you think you need a system overhaul, let’s talk about tracing tools. Tracing tools help you track, find, and diagnose errors in multi-tiered applications with a fraction of the effort required if you go the manual route.
While it’s true that you need to make some system modifications when you first implement tracing, it’s one-time if you choose the right tool. Make sure the tool you choose follows the open standards for tracing outlined by OpenTelemetry. This way, you can easily switch between vendors if your tracing requirements change.
Popular tools that adhere to these standards include open-source options such as Jaeger and Zipkin. Coralogix’s distributed tracing screen also adheres to OpenTelemetry.
Now that you understand what distributed tracing is and how it works, let’s look at some best practices and challenges.
Although tracing is a powerful tool in your monitoring arsenal, it’s not always the best choice. Tracing is a resource-intensive process. Since you’re adding extra load to your application and logging each response, the amount of data produced can impact the application’s performance. And that’s the opposite of what we want to do.
The best way forward here is to sample the traces and only switch them on if your logs show an anomaly. Think of tracing as an emergency alarm that can help you diffuse challenging situations, but you don’t want it to keep ringing all the time.
Tracing your entire system can be complicated, expensive, and extensive. You need to first understand if it makes sense for your business.
For example, if your applications primarily run on legacy systems or are transitioning from legacy to modern systems, your components likely use different programming languages and frameworks. Retrofitting tracing in a system like this is complex and requires you to devote engineering time to this process. You might even introduce bugs while trying to make tracing work.
While implementing tracing, an iterative approach works best. You’ll need to prioritize common breaking points and critical services within your applications for tracing.
With this approach, you have to accept that there might be blind spots in your system. However, narrowing down those blind spots will be easier by the process of elimination. This would result in faster resolution times and effective troubleshooting. And once your application uptime improves, getting stakeholders to approve “tracing” sprints will be more straightforward.
Distributed tracing is critical to observability in a distributed system. With traces, you gain access to data that can help streamline many crucial processes, such as running tests in production, disaster recovery, or fault injection testing.
However, tracing cannot always be used as it can affect application performance. Thus, it’s crucial to implement the other pillars of observability, i.e., logs, metrics, and security to build a complete picture of what’s happening with your system. That’s why Coralogix’s full stack observability platform combines all four to help monitor your system at all times. Try us out today!

Tracing is often the last thought in any observability strategy. While engineers prioritize logs and metrics, tracing is truly the hallmark of a mature observability platform,…
Coralogix is not just another monitoring or observability platform. We’re using our unique Streama technology to analyze data without needing to index it so teams can…

Observable and secure platforms use three connected data sets: logs, metrics, and traces. Platforms can link these data to alerting systems to notify system administrators when…